Please add export document as PDF feature.
I also think this is an important feature to be able to share information out of Fibery.
I have been using pdfmonkey.io to generate pdfs from individual entities using an action button (doesn’t work for views because there are multiple entities or documents). It seems to work fine, but there is an know bug with getDocumentContent() method which causes some linked entities in Rich Text Areas to not be resolved and so your final PDF will have missing bits of content. There is an issue with embeded images as well as those can’t be accessed directly by another site.
Happy to share the workflow if that is useful to anyone.
That sounds really interesting. If you can share the action button code that would be really good, thanks.
Apologies for the delay in responding. Here is the code for the action button:
// this action button uses the pdfmonkey.io API to generate pdf
// documents from fibery records/entities
// Fibery API and HTTP services
const fibery = context.getService('fibery');
const http = context.getService('http');
const utils = context.getService("utils");
// define the time zone offset (has to be hardcoded right now)
const timeOffset = {{UTC_TZ_OFFSET}};
for (const entity of args.currentEntities) {
// get the meeting date (object with start and end)
const meetingDateTime = entity['Date'];
const meetingDateStart = new Date(meetingDateTime.start);
meetingDateStart.setHours(meetingDateStart.getHours() + timeOffset);
const meetingDateEnd = new Date(meetingDateTime.end);
meetingDateEnd.setHours(meetingDateEnd .getHours() + timeOffset);
// get the subject of meeting (name of entity)
const meetingSubject = entity['Name'];
// get the meeting notes (RTF) field
const meetingNotes = entity['Notes'];
const notesContent = await fibery.getDocumentContent(meetingNotes.secret, "html");
// get collection fields query the API and provide the list of fields
const attendeeList = await fibery.getEntityById(entity.type, entity.id, ['Attendees']);
const nameArray = [];
attendeeList['Attendees'].forEach(function (person) {
nameArray.push(person.Name);
});
// call pdfmonkey.io api to generate the pdf document
const objDocument = await http.postAsync('https://api.pdfmonkey.io/api/v1/documents', {
body: {
"document": {
"document_template_id": "{{PDF_MONKEY_TEMPLATE_ID}}",
"payload": "{ \"subject\": \"" + meetingSubject + "\", \"datestart\": \"" + meetingDateStart + "\" , \"dateend\": \"" + meetingDateEnd + "\", \"attendees\": " + JSON.stringify(nameArray) + ", \"notes\": " + JSON.stringify(notesContent) + " }",
"status": "pending"
}
},
headers: {
'Content-type': 'application/json',
'Authorization': 'Bearer {{PDF_MONKEY_API_KEY}}' }
});
}
You will need to replace the following in the code:
- {{UTC_TZ_OFFSET}} : replace with your timezone offset (-12 to +12)
- {{PDF_MONKEY_TEMPLATE_ID}} : replace with your pdfmonkey.io template ID
- {{PDF_MONKEY_API_KEY}}: replace with your pdfmonkey.io API key
I would like to add to the code to wait for the PDF to be generated and then grab the address and store it a field in the entity. I will update the codes once I’ve done that.
The template in PDF monkey can be as simple or complicated as you wish:
HTML Template
<table class="letterhead">
<tr style="height: 40px">
<td class="logobox" rowspan="3">LOGO</td>
<td class="title" colspan="5">Meeting Notes</td>
</tr>
<tr style="height: 25px">
<td style="width: 80px; font-weight: bold">Subject:</td>
<td style="width: 500px; border-bottom: 1px solid #ddd;" colspan="4">{{subject}}</td>
</tr>
<tr style="height: 25px">
<td style="width: 80px; font-weight: bold">Project:</td>
<td style="width: 500px; border-bottom: 1px solid #ddd;">{{project}}</td>
<td style="width: 5px; font-weight: bold"></td>
<td style="width: 45px; font-weight: bold">Date:</td>
<td style="width: 150px; border-bottom: 1px solid #ddd;">{{datestart | date: "%Y %b %-d" }}</td>
</tr>
<tr style="height: 25px">
<td style="width: 120px"></td>
<td style="width: 80px; font-weight: bold">Location:</td>
<td style="width: 500px; border-bottom: 1px solid #ddd;">{{location}}</td>
<td style="width: 5px; font-weight: bold"></td>
<td style="width: 45px; font-weight: bold">Time:</td>
<td style="width: 150px; border-bottom: 1px solid #ddd;">{{datestart | date: "%k:%M" }} - {{dateend | date: "%k:%M" }}</td>
</tr>
</table>
<table class="letterhead">
<tr style="height: 10px">
<td style="width: 13px"></td>
<td></td>
</tr>
<tr style="height: 2px">
<td></td>
<td style="border-bottom: 1px solid #000;"></td>
</tr>
<tr style="height: 2px">
<td></td>
<td style="border-bottom: 1px solid #000;"></td>
</tr>
<tr>
<td></td>
<td style="font-weight: bold">Attendees</td>
</tr>
<tr style="">
<td></td>
<td>
<ul style="list-style-type: square">
{% for attendee in attendees %}
<li>{{attendee}}</li>
{% endfor %}
</ul>
</td>
</tr>
<tr style="height: 2px">
<td></td>
<td style="border-bottom: 1px solid #000;"></td>
</tr>
<tr style="height: 2px">
<td></td>
<td style="border-bottom: 1px solid #000;"></td>
</tr>
<tr>
<td></td>
<td style="font-weight: bold">Notes</td>
</tr>
<tr>
<td></td>
<td class="notecontent">{{notes}}</td>
</tr>
</table>
CSS
.letterhead {
width: 100%;
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Oxygen, Ubuntu, Cantarell, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif;
font-size: 11pt;
}
.title {
font-size: 22pt;
font-weight: bold;
}
.logobox {
width: 120px;
}
.notecontent{
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Oxygen, Ubuntu, Cantarell, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif;
}
Data Structure
{
"subject": "Test Meeting Notes",
"project": "Testing",
"datestart": "2021-03-05T11:00:00.000Z",
"dateend": "2021-03-05T20:00:01.000Z",
"location": "",
"attendees": ["Brian Griffin", "James Woods", "Peter Griffin"],
"notes": "This is a test"
}
Just a few caveats:
- It seems at the moment that entity references do not resolve properly and sometimes are missing from the HTML that is returned by Fibery. The team is aware of this but I don’t know when a fix is going to be provided
- Images in rich text area are not accessible outside of Fibery without some sort of authentication. So if you have images, those won’t should up in the generated PDF
I think it would be much better if Fibery had an internal capability to do this. I will link to this thread from the Templates thread because I think the two are related.
To expand on that, a « PDF generator » would be an amazing feature, with the ability to edit your text and formatting and insert variables from the item.
Could be used to generate quotes, invoices, contracts, reports…
Completely agree.
To use Fibery as a CRM it needs:
- email integration => just released but it will need other ways to integrate emails (forward emails to a specific address, chrome extension to integrate with gmail UI and allow to add an email to an entity)
- pdf generation for invoices => the above code is a good workaround
- better handling of duplicates entities: for now the system does not help to prevent duplicates (search too limited, no warning when 2 entities seems similar, etc)
- better way to add Accounts and Contacts from the web: web clipper to quickly add company from their website or linkedin page, add contact from their linked page or email (in gmail)
You can create a custom JS button to check the current database based on your duplicate rules.
If you fully understand what fields you want to collect I suggest creating two forms with API integration to Fibery.
Yes, these two are workarounds, but it’s better than nothing ![]()
Indeed, I would like to see more work on the existing web clipper to enable interaction with Fields, etc.
checking duplicates existence once they have been created is a really really lame way to handle it.
Fibery is a knowledge management tool, making sure that the knowledge is not duplicate (hence also avoiding scattering relationship on multiple similar entities) is hight priority. Addressing that an the input time is madatory.
Issues that most tools that tried to be the knowledge platform for a groupe/company are:
- no organisation of the knowledge => folders, graph, relationship etc are some answers to that
- no structure to hold the knowledge for similar type of information => being too freeform is ok for individual usage, but for a group you need guidelines, even better when those are enforced as the structural level. Fibery Type are answering that problem
- duplicates content => identical duplicates are easier to chase, difficulty is with almost duplicates, ie someone add a Company entity for “TotalEnergy” and start to add relationship, whereas there is already a “Total” entity in the system. A good example is the contacts app: google contact is really bad to find potential duplicates and suggest to merge. It would be much better to suggest when creating the potential duplicate
- no way to retrieve/recall the information when needed => lots of cases where zealous people store knowledge, but it is almost not used when needed, because too much friction to use (slow app, bad UX, bad navigation) or search not powerful enough. Fibery search is too limited for now (also linked to having to create multiple types to create complex relationships, some of those are more “helpers types” and don’t need to be searchable by default, but still clutter F search interface, since all types are first class citizens)
I am hoping that with the “block” re-write that is currently underway, the Fibery team is looking at baking a templating system from the ground up into Fibery that would drive the default interface but also allow users to customize how things render to high level of detail. This would also extend to outputs (pdf, text, csv, etc.). I know building an intuitive template editor system is a big task, so I will settle for a system that is basically requires the users to know basic html/css/templating syntax to make this happen.
I can see this helping with so many issues and opening up possibilities of new add-ons/plugins in the near future (add-ons being really what propel platforms forward into areas that the core team is unable to pursue).
I completely agree with these observations. I hope with time we will fix all that.
Any updates on this guys? The main idea of using Fibery is to keep everything in the one place. But we still need to copy Fibery documents data to Google Doc or MS Word and export them as PDF. 2 years of waiting ![]()
Would you be looking to export a document manually, or do you need PDF generation to be automated?
For the former, have you tried just using print-to-pdf from your browser?
For the latter, have you considered a Make or Zapier scenario?
hi! any updates on this?
sadly printing a document does not lead to usable pdfs at text is simply cut through if it hits the margins
ill look into the button thing, but it would be really great to have a simpler way of getting a pdf of a simple document out?
There has been some movement on this with the Oct 5 release:
This seems very encouraging, although I haven’t fully tested it out as a solution.
Hi Fibery team ![]()
Will this in the near future be implemented? I am not asking for workarounds or coding solutions that I don’t understand. I mean a native export solution.
Thank you!
Agreed, we had a need to export some pages, and the botched up images are quite annoying
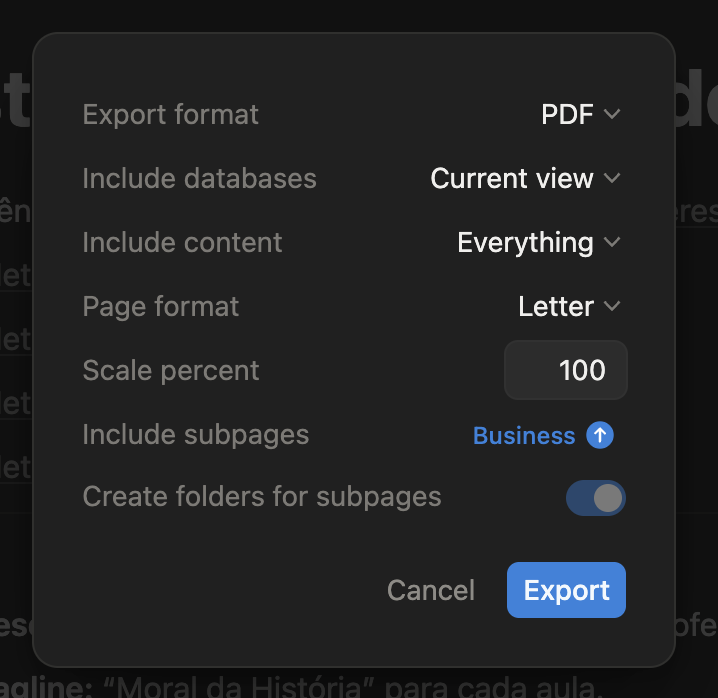
There’s a way to generate HTML PDF with Button automations. And if you need to print the entire entity page you can use your browser’s print feature.
Thanks for the suggestion, I already tried the print to pdf from my browser many times, there is no way to say that nice, it’s horrible, the formatting, text is cropped, tables, views, everything cropped or just weird.
And like I mentioned before, buttons and automation I believe it to be a workaround, most text editors or apps allow a native PDF export with one click, that is what we are currently asking for. ![]()