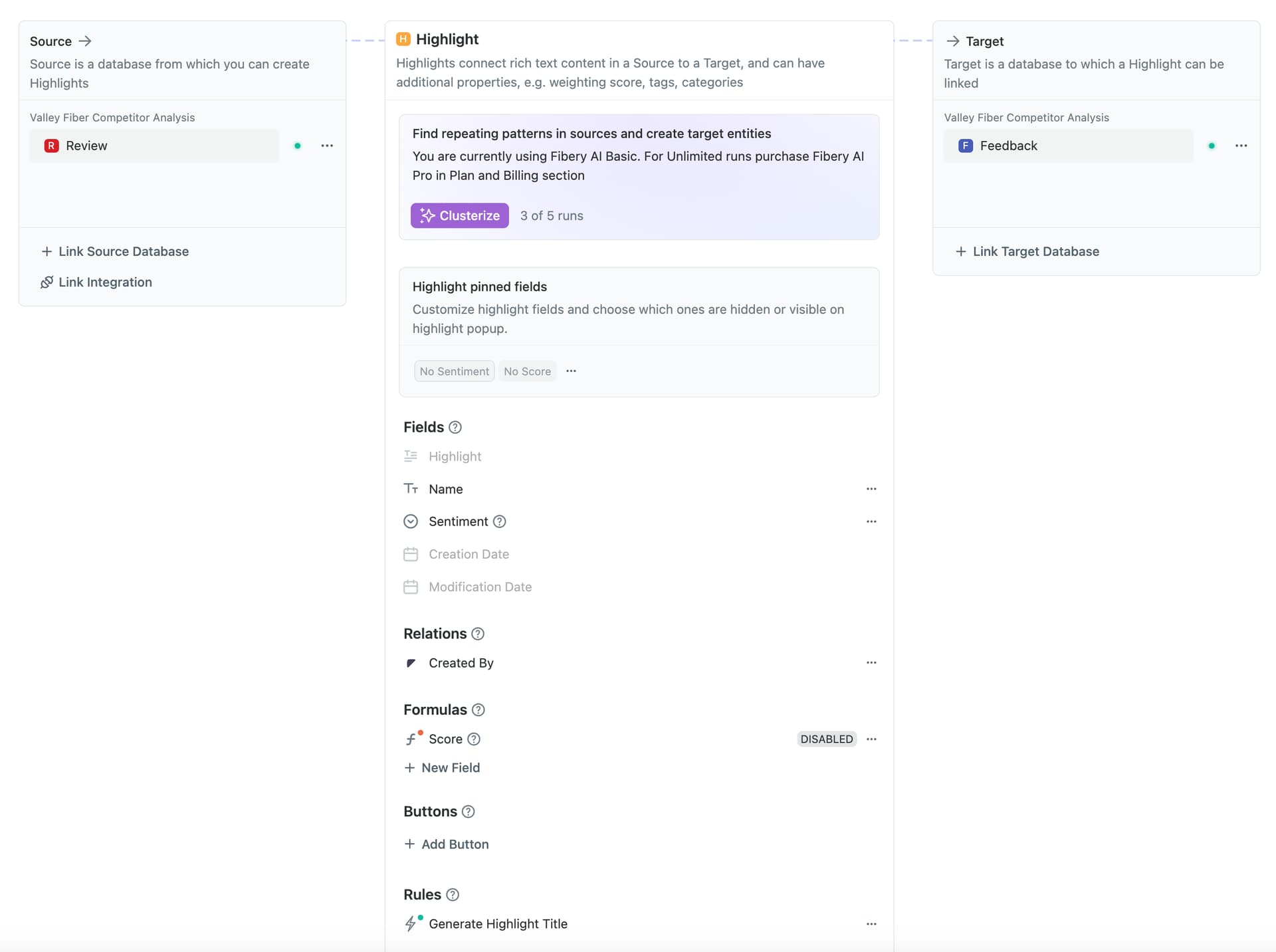
I have a few questions about how clustering works and some strange behavior I’m seeing when using it. I have 2 enetities, Review and Feedback. The goal is to aggregate a bunch of reviews (currently 132) and then use the clusterize feature to generate highlights and created Feeback entities. We want to see if there common themes amongst the reviews. Here’s a screenshot of what I have so far:
When I create the Feedback database and link it, how does the AI know what Feedback is? How does it know what criteria to cluster the data on? For example, what if I made a linked database called cats and I wanted to cluster all reviews that mentioned cats? Does the AI simply infer this from the title of the databse? Does it also use the description of the database?
When I do run the above cluster, I only end up with 1 entity in the Feedback database and it’s centered around a few poistive reviews about the service. Reading through the reivews, there’s many negative reviews that are all similar about some of the usual things like billing issues, and delivery delays. Why didn’t the clustering pick this up. Is 132 reviews just to small of a sample set?
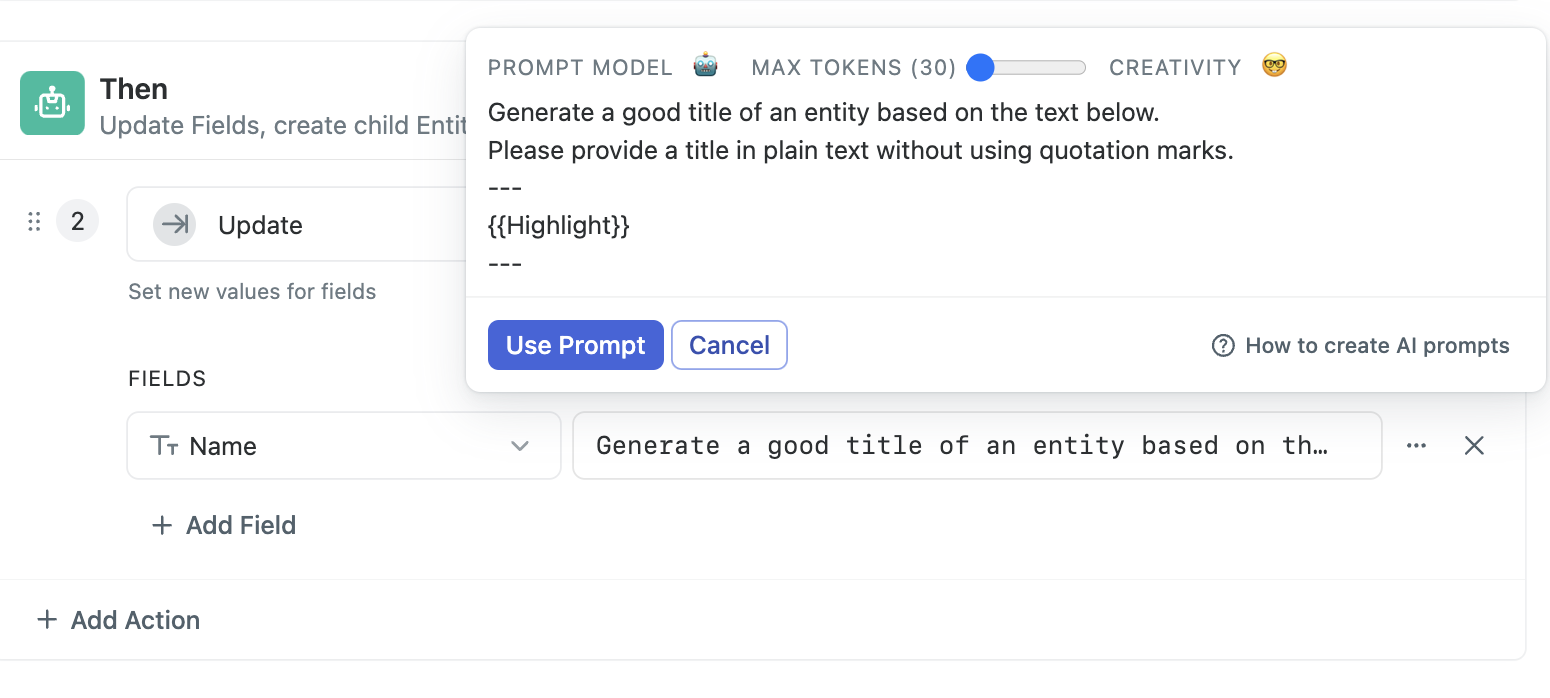
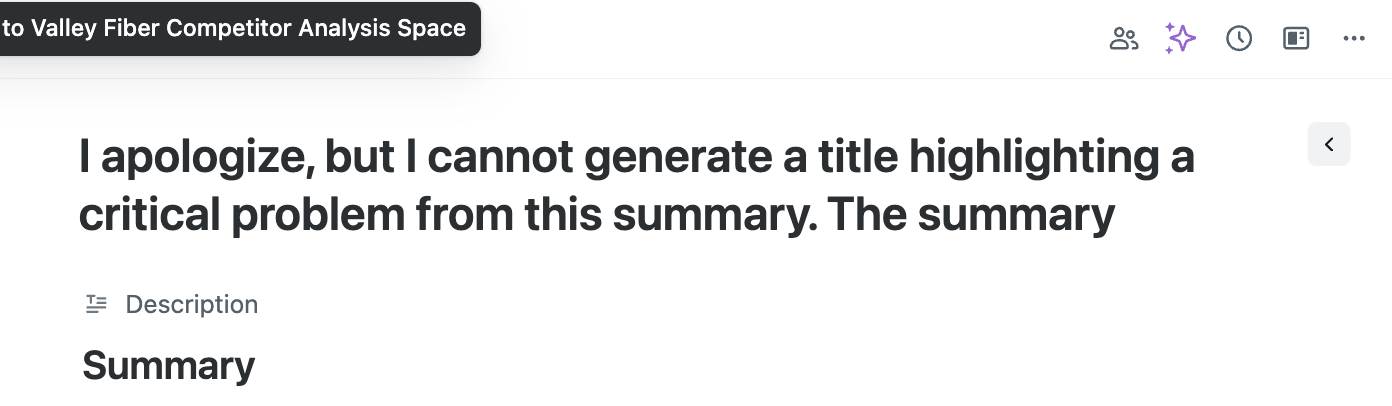
It also generated a weird title for the Feedback entity “I apologize, but I cannot generate a title highlighting a critical problem from this summary. The summary”. I’m using the default Rule for generating the title. I don’t see anything in that rule about generating a name based off of a “critical problem”. Why would I be seeing this unusual title?
What minimum size sample should we be using for the cluster feature?
Any help would be much appreciated. Sorry if I’m simply misunderstanding this feature and some of these questions don’t make sense. I’m simply trying to sift through a database of reviews and get some useful highlights and I was hoping clustering would help with that.
Thank you for the very detailed question! Let me shed some light here.
Feedback processing was implemented to handle massive amount of feedback, so you need a lot of items to make it useful, like few thousands of items in a database. This is why you have only 1 result. Minimal size depends on text volume in every review item, if they are quite short reviews than 1000 maybe will be a good starting point.
The algorithm is pretty complex, but in short it Review text to paragraphs and tries to find clusters in these paragraphs using several runs, then rejects low-quality clusters and only return what we call good-enough clusters. In your case it might happen than there are not many paragraphs and not many good clusters were found. Maybe we should add some settings to relax these conditions…
Technically the algorithm knows nothing about databases, it has two modes to find how to say it Issued and Features/Ideas, it will not work well with finding cats, for example.
It is strange that title was not generated, can you provide Summary text for us to check?
I very much hope this can be generalized with time! This is a good sort of test case (current implementation/focus), but relatively narrow in scope compared to the potential (IMHO).
I ended up bringing in over 7700 reviews and I still only ended up with 1 Feedback after running the clustering. So I’m not sure if I’m doing something wrong or have it setup incorrectly.
Seems like you have to manually re-index the data. Now I got 13 Feedback created. I had expected that when you click Cluster, that the data would automatically go through a re-index in the background.